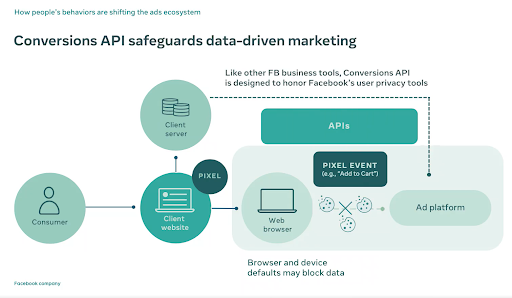
Il Server Side Tagging è una soluzione di tracciamento recentemente molto discussa per i suoi vantaggi. A differenza del Client Side Tagging, una soluzione di tracciamento lato server sposta l’elaborazione e l’invio dei dati raccolti dal dispositivo finale dell’utente al server.
Il Server Side Tagging comporta diversi vantaggi, sia per gli utenti che per le aziende. In primis, le aziende che lo adottano diventano pienamente proprietarie dei dati raccolti, potendo gestire in maniera strategica cosa fare dei propri dati. Spostare l’onere di raccolta dati al server migliora inoltre le prestazioni del proprio sito, garantendo un’esperienza utente e una SEO tecniche migliori.
I dati raccolti attraverso un sistema server-side possono essere elaborati ed integrati da diverse fonti prima di inviarli ad altri servizi, aprendo nuove opportunità di analisi. Infine, una soluzione Server Side permette di non dipendere per la raccolta dati da cookie di terze parti (ormai bloccati da sempre più dispositivi); questo ovviamente dovendo rispettare i consensi espressi dagli utenti.
Tale soluzione non è priva di svantaggi: comporta un aumento dei costi per la gestione dei server ed implica la responsabilità delle aziende nel rispetto dell’utilizzo dei dati raccolti. Si tratta inoltre di una soluzione non ancora pienamente matura, ma sul quale l’attenzione crescente di grandi aziende potrebbe portare presto novità.
Capire se una soluzione Server Side fa al caso proprio deve essere una scelta strategica da valutare attentamente, avvalendosi dell’esperienza di professionisti.
Introduzione: che cosa è il Server Side Tagging?
Il termine Server Side Tagging è di sicuro uno dei più caldi per chiunque si occupi di digital analytics, e per ottime ragioni.
Si tratta di una tecnologia già da tempo sul mercato (Google l’ha annunciato nella Superweek 2020 e qui puoi leggere il nostro resoconto), ma che recentemente ha raccolto sempre più interesse. Una ragione di questo interesse è sicuramente l’attuale contesto digitale, dominato da discussioni su temi come privacy, proprietà dei dati e ruolo delle Big Tech.
In questo clima di cambiamenti inaspettati e allarmismi sull’uso di tecnologie (vedi il caso di Google Analytics “dichiarato illegale” in Austria), una soluzione di Server Side Tagging è diventata sempre più interessante per chi voglia continuare a raccogliere dati sui canali digitali, ma voglia tutelarsi da molti problemi che questo comporta.
Vediamo assieme di cosa significa utilizzare una soluzione di Server Side Tagging, quali vantaggi e svantaggi offre, e come capire se fa al caso tuo.
Qual è la differenza tra Client-side e Server-side tagging?
Per capire di cosa si tratta, occorre fare un piccolo passo indietro su come funziona a grandi linee il web.
Nella navigazione online, esistono due grandi sfere di attività: il lato client ed il lato server.
Per spiegare in che modo questi due ambiti interagiscono, può essere utile adoperare la metafora di un ristorante.
Vi sono clienti che ordinano piatti, camerieri che prendono e portano gli ordini ed una cucina che li riceve, prepara e fa uscire una volta pronti.
Il lato client, ovvero quello dei clienti, è quello dove sarà possibile vedere quanto richiesto; l’insieme di informazioni e codici che inviati al proprio dispositivo ci permette di visualizzare prodotti digitali come una pagina web.
Il lato server è invece dove vengono ricevute le richieste di informazioni dagli utenti finali, si ricercano e preparano i dati necessari, ed infine vengono inviati agli utenti finali.
Sicuramente usare un ristorante per spiegare come funziona internet è una semplificazione. Ma se applichiamo lo stesso modello per miliardi di clienti che possono mandare innumerevoli richieste a milioni di cucine e che questo scambio avviene in pochi millisecondi, si arriva a comprendere come funzioni il tutto.
Come si applica al Tagging?
Nella digital analytics, l’uso di soluzioni di tagging (i.e. Google Tag Manager) permette di impostare un sistema di raccolta dati efficiente senza il bisogno di tempi di sviluppo. Tutto questo si svolge solitamente lato client, caricando assieme al contenuto richiesto stringhe di codice necessarie per raccogliere informazioni su come l’utente utilizzi un sito. Le informazioni vengono raccolte e inviate direttamente lato client a servizi esterni come Google Analytics o Facebook, che le utilizzeranno per altri prodotti.
Fin qui sembra tutto abbastanza chiaro, ma riprendiamo la metafora del ristorante per capire in che modo questa soluzione possa fallire.
Un cliente ordina un piatto da mangiare, la cameriera porta la richiesta in cucina (il server) che si occupa di preparare il piatto richiesto. Nell’inviare il piatto al cliente, la cucina aggiunge alcuni ingredienti da assaggiare assieme a piacere (gli script di tracciamento). Questi servono per aiutare la cucina a capire cosa piace al cliente (i.e. Analytics) e permettere ad altre cucine di offrire al cliente piatti simili (i.e. servizi di advertising).
A questo punto il cliente si troverà ad avere, oltre al suo piatto, diversi ingredienti da assaggiare assieme a suo piacimento. Ma per indicare una sua preferenza dovrebbe essere lui stesso a portare indietro i piatti vuoti per indicare cosa gli è piaciuto; non ad una singola cucina ma alle diverse cucine che si occupano di quegli ingredienti!
Inutile dire che molti clienti non avranno alcun interesse a riportare indietro i piatti e dire cosa è piaciuto e cosa no. Inoltre, con troppi ingredienti extra al tavolo sarebbe più difficoltoso mangiare (o visitare un sito) e genererebbe una pessima esperienza.
Quello che abbiamo appena descritto è sostanzialmente la condizione attuale delle soluzioni di tracciamento client-side, in cui l’onere di raccogliere ed inviare le informazioni è in carico agli utenti finali; in cui aggiungere troppi servizi esterni ai propri tracciamenti può appesantire eccessivamente la navigazione, rendendo poco piacevole l’esperienza utente su un sito.
Per ovviare a questi ed altri problemi, la soluzione migliore è passare ad una soluzione lato Server
Come funziona il Server Side Tagging?
Non entreremo nel tecnico (per chi volesse, ne abbiamo parlato in un articolo dedicato), ma occorre capire in che modo il Server Side Tagging si distingua dal Client Side.
In primis, chiariamo che le due soluzioni non sono esclusive l’una dell’altra. Anzi possono e dovrebbero convivere per assicurarsi una soluzione di digital analytics completa.

Mentre nel tagging client side l’onere di elaborare ed inviare i dati viene demandato agli utenti, nel Server Side Tagging, una volta ricevute dal client le informazioni, l’intera attività di elaborazione ed invio viene gestita dai server stessi.
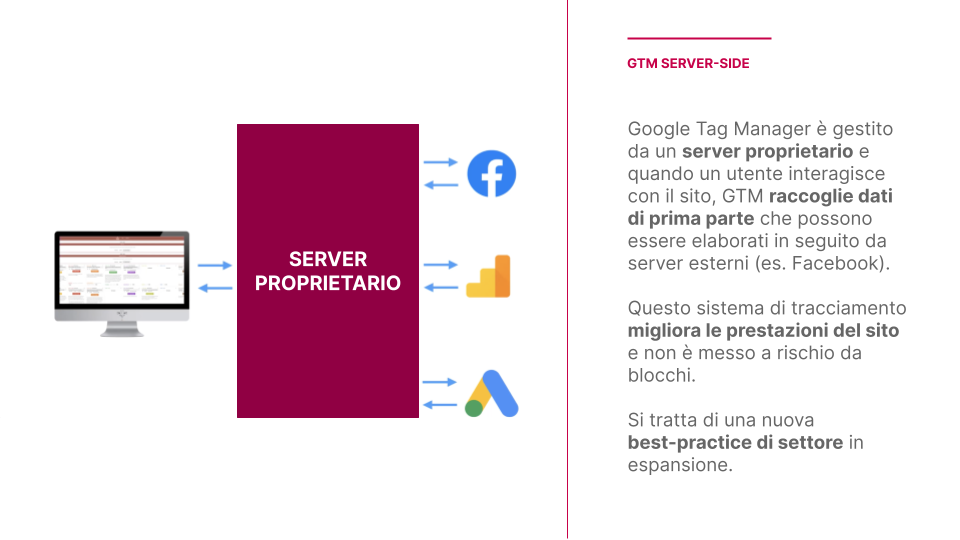
Per tornare alla metafora, il cliente dopo aver consumato il pasto non dovrà occuparsi personalmente di portare i piatti vuoti a diverse cucine, ma basterà che li riporti alla prima cucina a cui si è rivolto, la quale si occuperà in prima persona di capire cosa ha mangiato e cosa ha apprezzato, comunicandolo ad altre cucine interessate.
Sicuramente un bel risparmio di fatica per il cliente, che porta potenzialmente agli stessi se non a migliori risultati che nella soluzione lato client.
Come ogni cosa però una soluzione Server Side comporta alcuni svantaggi che vale la pena approfondire.
Quali sono i vantaggi del Server Side Tagging?
Vediamo nel dettaglio i vantaggi di una soluzione di tagging server side.
1. Migliori prestazioni del sito
Come già menzionato, adottare una soluzione Server Side significa ridurre la necessità lato client di caricare diversi script per inviare dati. Questa riduzione delle informazioni da inviare si traduce in una maggiore efficienza e velocità del caricamento pagine, migliorando sia l’esperienza utente che la SEO tecnica del proprio sito.
2. Pieno controllo dei dati raccolti
Implementare una soluzione server significa aggiungere un layer aggiuntivo di filtro, dove è possibile decidere come gestire i dati raccolti, quali elaborazioni svolgere e dove inviarli. Questo permette di essere certi di escludere informazioni sensibili o personali dai dati inviati a servizi terzi (come mail o password); così come essere certi di inviare la stessa informazione a diversi punti assicurando così la coerenza dei dati su diversi sistemi.
3. Mitigazione del blocco di cookie di terze parti
Applicare un tracciamento lato server significa non dover più dipendere obbligatoriamente da cookie di terze parti per inviare loro informazioni. Diventa infatti possibile non impostare per nulla tali cookie lato client ma gestire l’invio di informazioni totalmente lato server. Attenzione però: questa possibilità non implica che sia possibile non considerare le preferenze espresse dall’utente in termini di trattamento dei dati. Tali consensi dovranno sempre essere rispettati, ma sarà possibile non essere penalizzati da browser e sistemi operativi che blocchino a priori i cookie di terze parti.
4. Possibilità di integrare dati da diverse fonti
Infine, avere una soluzione Server Side significa poter non solo raccogliere dati dal proprio sito, ma poterli arricchire grazie ad informazioni di altri servizi utilizzati. Diventa infatti possibile collegare Analytics al proprio CRM, aggiungendo informazioni dal CRM agli Analytics e al contempo registrare le interazioni svolte dall’utente. La possibilità di incrociare ed elaborare dati da diverse fonti permette in tal modo di espandere notevolmente le capacità di analisi.
Quali sono gli svantaggi del Server Side Tagging?
Il Server Side Tagging, per quanto rappresenti diversi vantaggi rispetto al Client Side, ha alcuni importanti svantaggi da considerare:
1. Raccolta dati opaca
Le soluzioni Server Side spostano l’attività di raccolta dati nel “dietro le quinte”, rendendo effettivamente difficile per gli utenti sapere in che modo i loro dati vengano raccolti e ancora più difficile dove vengono inviati.
Se infatti con le soluzioni Client side per inviare dati a servizi esterni è necessario impostare cookie di terze parti, che permettono di risalire al servizio in questione, con una soluzione Server Side questo principio crolla, in quanto i dati raccolti saranno inviati solo successivamente dal server, non dandone visibilità chiara all’utente.
2. La gestione del consenso è in mano alle aziende
Adottando una soluzione server side, l’invio dei dati da parte del cliente passa da diversi flussi diretti a molteplici servizi, ad un singolo flusso diretto al server. Questo significa che il modo in cui i dati vengano raccolti ed inviati è completamente in carico alle aziende, che dovranno occuparsi di elaborare e smistare i dati in modo tale da rispettare il consenso espresso dagli utenti all’uso dei loro dati.
3. Costo
Per poter effettivamente usufruire di una soluzione lato server è richiesto, appunto, un server. Tale server può essere proprietario o affittato tramite servizi cloud come Google Cloud Platform, che offre inoltre il grande vantaggio di essere integrabile con l’ecosistema di servizi Google.
In ogni caso, tali server hanno costi di mantenimento, seppur solitamente ridotti, che vanno considerati in fase di decisione.
4. Bassa maturità del servizio
Anche se si tratta di una tecnologia abbastanza consolidata, sono ancora diversi i servizi che non dispongono dell’infrastruttura web necessaria per essere integrati con le soluzioni di tracciamento lato server. Questo punto andrà sempre più a ridursi con la progressiva adozione di questa soluzione e il relativo interesse a sviluppare un ecosistema integrato attorno ad essa.
Vuoi implementare il Server Side Tracking?
Il Server Side Tracking rappresenta un'importante innovazione nel panorama del Digital Analytics, garantendo alle aziende di diventare realmente proprietari dei dati raccolti sui loro siti. Questo vantaggio chiave porta con sé grandi opportunità ma anche importanti svantaggi da considerare.
In ultima analisi, la valutazione di fattibilità e convenienza di questa soluzione deve essere una scelta ragionata e tenere conto delle specificità della propria azienda.
Diciamo che in linea di massima il Server-Side tracking è la soluzione migliore per:
- Chi fa investimenti consistenti in advertising ed é interessato a mantenere o migliorare le performance
- Aziende data-driven per cui l’affidabilità del dato é importante
Se pensi che sia quello di cui hai bisogno in azienda, o semplicemente vuoi saperne di più, contattaci scrivendo a hello@digitalpills.it e saremo felici di aiutarti!